|
I am a research scientist at OpenAI on the Sora team. I was previously a PhD student at the University of Michigan advised by Andrew Owens, where I studied computer vision. I have also had the pleasure of working with Charles Herrmann and Deqing Sun at Google DeepMind as a student researcher, Lorenzo Torresani and Huiyu Wang as an intern at FAIR, and Sergey Levine, Coline Devin, Alyosha Efros and Taesung Park as an undergrad at UC Berkeley. Github / Google Scholar / Twitter / Email |

|
|
I am interested in generative models, how we can control them, and novel ways to use them. I've also worked on levarging differentiable models of motion for image and video synthesis and understanding, and in the past I've worked on representation learning, multimodal learning, and reinforcement learning. |
|
|
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Tatiana Lopez-Guevara, Carl Doersch, Yusuf Aytar, Michael Rubinstein, Chen Sun, Oliver Wang, Andrew Owens, Deqing Sun CVPR, 2025 (Oral) We train a video generation to be conditioned on motion, and then prompt it with motion prompts, elliciting a wide range of behavior. arXiv / webpage |
|
|
Ziyang Chen, Daniel Geng, Andrew Owens NeurIPS, 2024 We use diffusion models to make spectrograms that look like natural images, but also sound like natural sounds. arXiv / webpage / code |

|
Daniel Geng*, Inbum Park*, Andrew Owens ECCV, 2024 Sister project of "Visual Anagrams." Another zero-shot method for making more types of optical illusions with diffusion models, with connections to spatial and composition control of diffusion models, and inverse problems. arXiv / webpage / code |
|
|
Daniel Geng, Inbum Park, Andrew Owens CVPR, 2024 (Oral) A simple, zero-shot method to synthesize optical illusions from diffusion models. We introduce Visual Anagrams—images that change appearance under a permutation of pixels. arXiv / webpage / code / colab |
|
|
Daniel Geng, Andrew Owens ICLR, 2024 We guide diffusion sampling using off-the-shelf optical flow networks. This enables zero-shot motion based image editing. arXiv / webpage / code |
|
|
Daniel Geng*, Zhaoying Pan*, Andrew Owens NeurIPS, 2023 By differentiating through off-the-shelf optical flow networks we can train motion magnification models in a fully self-supervised manner. arXiv / webpage / code |
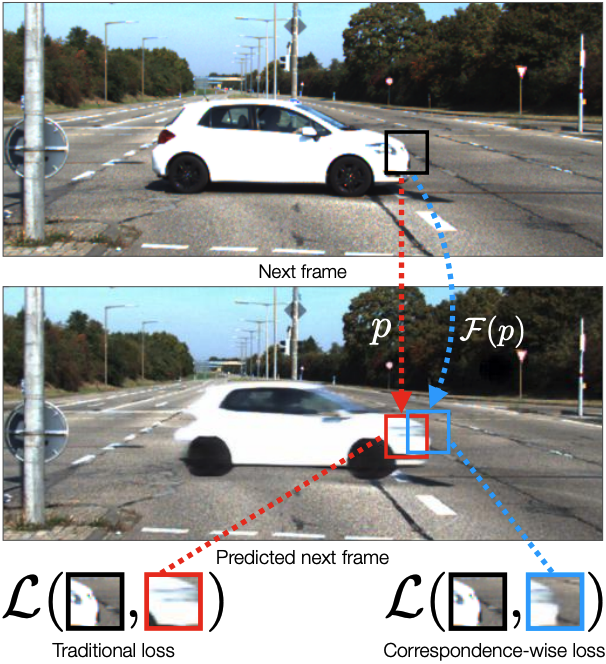
|
Daniel Geng, Max Hamilton, Andrew Owens CVPR, 2022 Pixelwise losses compare pixels by absolute location. Instead, comparing pixels to their semantic correspondences surprisingly yields better results. arXiv / webpage / code |

|
Glen Berseth, Daniel Geng, Coline Devin, Nicholas Rhinehart, Chelsea Finn, Dinesh Jayaraman, Sergey Levine ICLR, 2021 (Oral) Life seeks order. If we reward an agent for stability do we also get interesting emergent behavior? arXiv / webpage / oral |
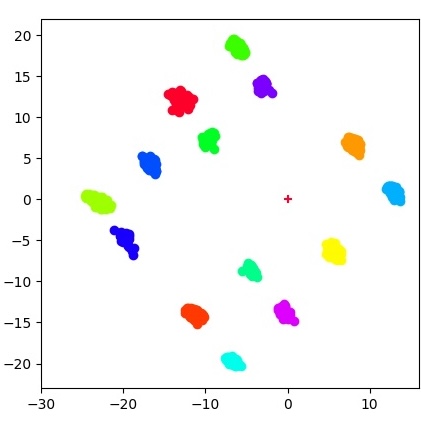
|
Coline Devin, Daniel Geng, Trevor Darrell, Pieter Abbeel, Sergey Levine NeurIPS, 2019 Learning a composable representation of tasks aids in long-horizon generalization of a goal-conditioned policy. arXiv / webpage / short video / code |
|
Website template from Jon Barron.
|