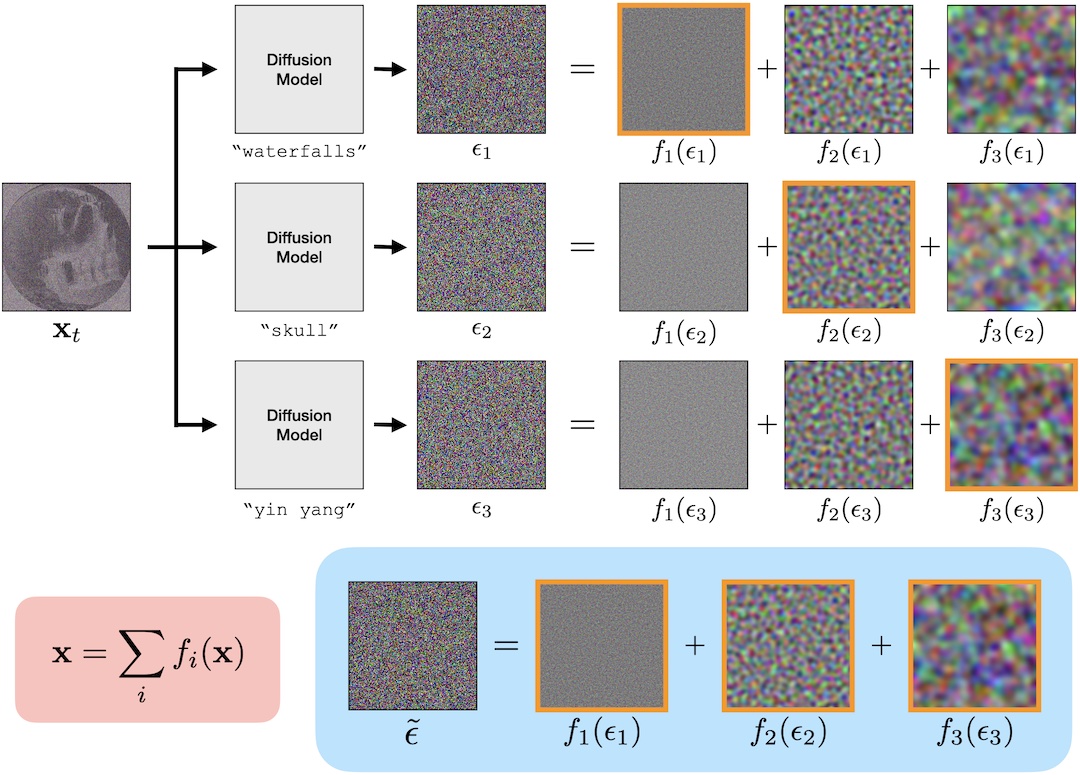
Diffusion models update noisy images, \(\mathbf{x}_t\), to less
noisy images, \(\mathbf{x}_{t-1}\), with an \(\texttt{update}(\cdot,\cdot)\) function1.
Commonly used update functions include DDPM and DDIM, and are
linear combinations of the noisy image, \(\mathbf{x}_t\), and
the noise estimate \(\epsilon_\theta\).2
That is, these updates can be written as
\[ \begin{aligned} \mathbf{x}_{t-1} &= \texttt{update}(\mathbf{x}_t, \epsilon_\theta) \\ &=\omega_t \mathbf{x}_t + \gamma_t \epsilon_\theta \end{aligned} \]
where \(\omega_t\) and \(\gamma_t\) are determined by the variance schedule and the scheduler. Then given a decomposition \( \mathbf{x} = \sum f_i(\mathbf{x}) \), this
means the update rule can be decomposed into a sum of updates on components:
\[ \begin{aligned} \mathbf{x}_{t-1} &= \texttt{update}(\mathbf{x}_t, \epsilon) \\ &= \texttt{update}\left( \sum f_i(\mathbf{x}_t), \sum f_i(\epsilon) \right) \\ &= \sum_i \texttt{update}(f_i(\mathbf{x}_t), f_i(\epsilon)) \end{aligned} \]
where the last equality is by linearity of \( \texttt{update}(\cdot,\cdot) \).
Our method can be understood as conditioning each of these
components on a different text prompt. Written explicitly,
for text prompts \( y_i \) our method is
\[ \begin{aligned} \mathbf{x}_{t-1} = \sum_i \texttt{update}(f_i(\mathbf{x}_t), f_i(\epsilon(\mathbf{x}_t, y_i, t))). \end{aligned} \]
Moreover, if the \( f_i \)'s are linear then we have
\[ \begin{aligned}
f_i(\mathbf{x}_{t-1}) &= f_i(\texttt{update}(\mathbf{x}_t, \epsilon)) \\
&= f_i(\omega_t\mathbf{x}_t + \gamma_t\epsilon_\theta) \\
&= \omega_t f_i(\mathbf{x}_t) + \gamma_t f_i(\epsilon_\theta) \\
&= \texttt{update}(f_i(\mathbf{x}_t), f_i(\epsilon_\theta)),
\end{aligned} \]
meaning that updating using the \(i\)th component of
\(\mathbf{x}_t\) with the \(i\)th component of \(\epsilon_\theta\) will only affect
the \(i\)th component of \(\mathbf{x}_{t-1}\).